

Personal Introduction
About me
I’m a student from China University of Petroleum (East China)
- 👯 I’m going to Wuhan University for master’s degree
- 🌱 I’m currently learning LLM & JAVA
- 📫 How to reach me 15271228216@163.com
My Projects
Variable Selection for Spatial Autoregressive Models with constraints
Context: For the constrained variable selection problem, a method based on a penalized spatial autoregressive model is proposed, utilizing a quasi-maximum likelihood loss function and a penalty function for variable selection within the spatial autoregressive model.
[project]
Ying Shi: A Poetry Creation Platform Based on Visual Encoding and Natural Language Generation
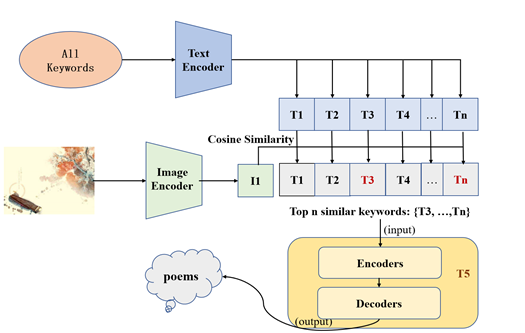
This platform identifies keywords by recognizing images uploaded by users and then generates verses based on the identified keywords.
Contributions:
- Encode the input image using the CLIP model, compute the cosine similarity between the image encoding and the keyword encodings, and extract the top 5 keywords with the highest similarity.
- During the poetry generation phase, retrain a T5 model based on keywords and classical poetry. In the inference stage, generate lines of poetry based on the keywords matched in the previous phase.
[project]
Monocular 3D Human Body Shape and Pose Estimation Based on the SMPL Model
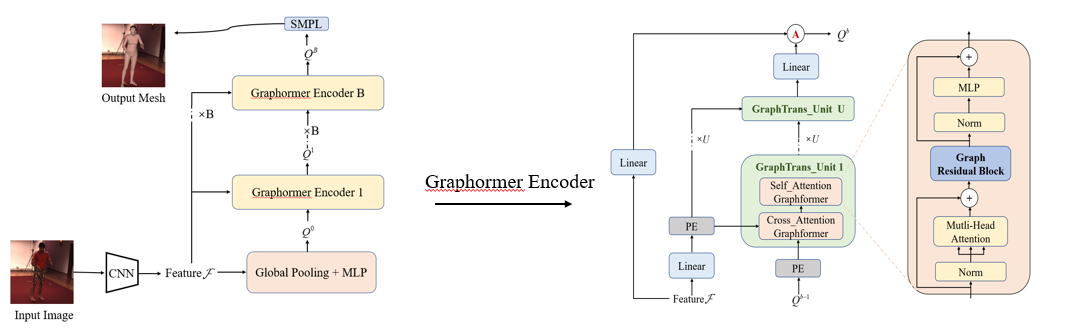
This project is dedicated to improving monocular 3D human body shape and pose estimation techniques, achieving efficient and accurate pose prediction based on the SMPL model. Experimental results demonstrate that this method significantly outperforms previous state-of-the-art approaches on multiple benchmarks, including the Human3.6M and 3DPW datasets.
- Contributions:
- The optimization of the VIT architecture, by introducing a decoupled attention mechanism, significantly reduces the complexity of feature computation, decreasing the computational cost from quadratic to linear.
- Graph Convolutional Networks (GCN) have been introduced for deep feature extraction of human joint representations, enhancing the model’s ability to capture spatial structural information and further optimizing the target representation.
- [project]