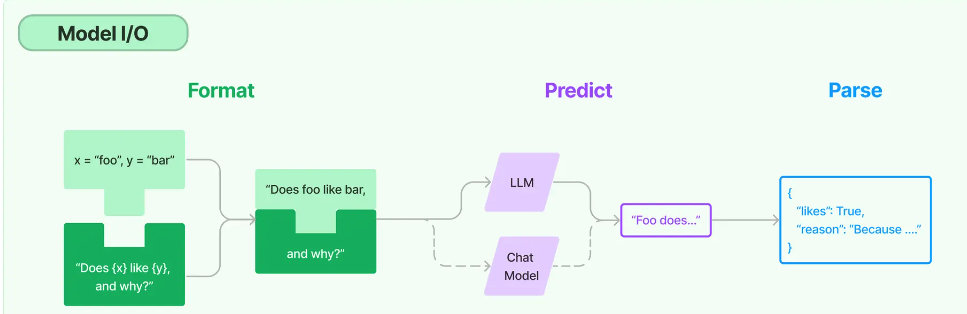
Model I/O 模型的使用过程:输入提示 + 调用模型 + 输出解析 (Model I/O)
1. 提示模板 具体原则:
给予模型清晰明确的指示
让模型慢慢地思考
2. 语言模型
大语言模型:Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。
聊天模型:Chat Model,主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
文本嵌入模型:Embedding Model,这些模型将文本作为输入并返回浮点数列表,也就是Embedding。
下面调用语言模型,让模型帮助我们写文案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain.prompts import PromptTemplateimport os from langchain_community.llms import HuggingFaceHub"http_proxy" ] = "http://localhost:7890" "https_proxy" ] = "http://localhost:7890" """您是一位专业的鲜花店文案撰写员。\n 对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗? """ print (prompt) "Qwen/Qwen2.5-Coder-32B-Instruct" , model_kwargs={"temperature" : 0.7 })input = prompt.format (flower_name = ["杏花" ], price = '30' )input )print (output)
1 春日里,温柔的杏花轻轻绽放,每一朵都承载着诗意的期盼。选择一束这样的杏花,让春意盎然的气息伴随您的每一天。
3. 输出解析 在开发具体应用的过程中,很明显我们不仅仅需要文字,更多情况下我们需要的是程序能够直接处理的、结构化的数据 。
下面,我们就通过LangChain的输出解析器来重构程序,让模型有能力生成结构化的回应,同时对其进行解析,直接将解析好的数据存入CSV文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 from langchain.prompts import PromptTemplateimport os from langchain_community.llms import HuggingFaceHubfrom langchain_huggingface import HuggingFaceEndpointfrom langchain.output_parsers import StructuredOutputParser, ResponseSchemaimport pandas as pdimport json"HUGGINGFACEHUB_API_TOKEN" ] = "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" "http_proxy" ] = "http://localhost:7890" "https_proxy" ] = "http://localhost:7890" """您是一位专业的鲜花店文案撰写员。 对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗? output只需要回复一个json格式的数据即可 {format_instructions}""" "Qwen/Qwen2.5-Coder-32B-Instruct" )"description" , description="鲜花的描述文案" ),"reason" , description="问什么要这样写这个文案" ),"format_instructions" : format_instructions}"玫瑰" , "百合" , "康乃馨" ]"50" , "30" , "20" ]import pandas as pd"flower" , "price" , "description" , "reason" ]) for flower, price in zip (flowers, prices):input = prompt.format (flower_name=flower, price=price)input )print (output)"flower" ] = flower"price" ] = pricelen (df)] = parsed_outputprint (df.to_dict(orient="records" ))"flowers_with_descriptions.csv" , index=False )
1 2 3 4 5 6 [{'flower ': '玫瑰 ', 'price ': '50 ', 'description ': '这束由精选玫瑰打造的浪漫之作,不仅承载着无尽的爱意,更散发着迷人的香气,每一朵都如同精心雕琢的艺术品,定能让您的爱意传递得更加 'reason ': '通过强调玫瑰的精选与艺术品般的特质,能够激发顾客对鲜花质量的关注,同时,提到无尽爱意和迷人香气,则能够触动顾客的情感,增加购买的欲望。 '},'flower ': '百合 ', 'price ': '30 ', 'description ': '优雅绽放,30元即可将这束纯洁的百合带回家,为您的空间增添一抹宁静与高雅。 ', 'reason ': '百合象征着纯洁与高雅,使用这些词汇可以吸引追求品质生活的顾客。 'flower ': '康乃馨 ', 'price ': '20 ', 'description ': '每朵康乃馨都承载着温柔的祝福,它们不仅色彩丰富,更蕴含着深深的情感。以20元的价格 'reason ': '通过描述康乃馨的温柔与情感,能够吸引那些寻求表达情感的顾客。同时,提到价格,使顾客觉得这份情感的表达既贴心又经济实惠,增加购买欲望。 '}]
首先定义输出结构,我们希望模型生成的答案包含两部分:鲜花的描述文案(description)和撰写这个文案的原因(reason)。所以我们定义了一个名为response_schemas的列表,其中包含两个ResponseSchema对象,分别对应这两部分的输出。
然后,我们通过输出解析器对象的get_format_instructions()方法获取输出的格式说明(format_instructions),再根据原始的字符串模板和输出解析器格式说明创建新的提示模板(这个模板就整合了输出解析结构信息)。再通过新的模板生成模型的输入,得到模型的输出。此时模型的输出结构将尽最大可能遵循我们的指示,以便于输出解析器进行解析。
提示工程 1. 提示的结构
指令:告诉模型这个任务大概要做什么、怎么做,比如如何使用提供的外部信息、如何处理查询以及如何构造输出。这通常是一个提示模板中比较固定的部分。一个常见用例是告诉模型“你是一个有用的XX助手”,这会让他更认真地对待自己的角色。
上下文:充当模型的额外知识来源。这些信息可以手动插入到提示中,通过矢量数据库检索得来,或通过其他方式(如调用API、计算器等工具)拉入。一个常见的用例时是把从向量数据库查询到的知识作为上下文传递给模型。
提示输入:具体的问题或者需要大模型做的具体事情,这个部分和“指令”部分其实也可以合二为一。但是拆分出来成为一个独立的组件,就更加结构化,便于复用模板。这通常是作为变量,在调用模型之前传递给提示模板,以形成具体的提示。
输出指示器:标记要生成的文本的开始。这就像我们小时候的数学考卷,先写一个“解”,就代表你要开始答题了。如果生成 Python 代码,可以使用 “import” 向模型表明它必须开始编写 Python 代码(因为大多数 Python 脚本以import开头)。这部分在我们和ChatGPT对话时往往是可有可无的,当然LangChain中的代理在构建提示模板时,经常性的会用一个“Thought:”(思考)作为引导词,指示模型开始输出自己的推理(Reasoning)。
2. LangChain 提示模板的类型
2.1 使用 PromptTemplate 1 2 3 4 5 6 7 8 9 10 from langchain import PromptTemplate"""\ 你是一个业务咨询顾问。 你给一个销售{product}的电商公司,其一个好名字? """ print (prompt.format (product = "鲜花" ))
输出:
1 2 你是一个业务咨询顾问。
这个程序的主要功能是生成适用于不同场景的提示,对用户定义的一种产品或服务提供公司命名建议。
PromptTemplate的from_template方法,我们创建了一个提示模板对象,并通过prompt.format方法将模板中的 {product} 替换为 "鲜花"。
在上面这个过程中,LangChain中的模板的一个方便之处是from_template方法可以从传入的字符串中自动提取变量名称(如product),而无需刻意指定。上面程序中的product自动成为了format方法中的一个参数 。
当然,也可以通过提示模板类的构造函数,在创建模板时手工指定input_variables,示例如下:
1 2 3 4 5 6 "product" ],print (prompt.format (product = "鲜花" ))
2.2 使用 ChatPromptTemplate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain.prompts import ("你是一位专业顾问,负责为专注于{product}的公司起名。" "公司主打产品是{product_detail}。" "鲜花装饰" , product_detail="创新的鲜花设计。" ).to_messages()import os"OPENAI_API_KEY" ] = '你的OpenAI Key' from langchain.chat_models import ChatOpenAIprint (result)
3. FewShot的思想 把Zero-Shot翻译为“顿悟”,聪明的大模型,某些情况下也是能够做到的。
在Few-Shot学习设置中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应。
在Zero-Shot学习设置中,模型只根据任务的描述生成响应,不需要任何示例。
3.1 FewShotPromptTemplate 使用FewShotPromptTemplate创建模板,能够使用多个示例来指导模型生成对应的输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 "flower_type" : "玫瑰" ,"occasion" : "爱情" ,"ad_copy" : "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。" ,"flower_type" : "康乃馨" ,"occasion" : "母亲节" ,"ad_copy" : "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。" ,"flower_type" : "百合" ,"occasion" : "庆祝" ,"ad_copy" : "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。" ,"flower_type" : "向日葵" ,"occasion" : "鼓励" ,"ad_copy" : "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。" ,from langchain.prompts.prompt import PromptTemplate"鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}" "flower_type" , "occasion" , "ad_copy" ] ,print (prompt_sample.format (**samples[0 ]))from langchain.prompts.few_shot import FewShotPromptTemplate"鲜花类型: {flower_type}\n场合: {occasion}" ,"flower_type" , "occasion" ]print (prompt.format (flower_type="野玫瑰" , occasion="爱情" ))
使用大模型创建新文案:
1 2 3 4 5 from langchain_huggingface import HuggingFaceEndpoint"Qwen/Qwen2.5-Coder-32B-Instruct" )format (flower_type="野玫瑰" , occasion="爱情" ))print (result)
文案: 野玫瑰虽然没有温室玫瑰那样娇艳,但它代表着自然的爱情,是送给爱人的一份惊喜。
3.2 使用示例选择器 示例选择器:来选择最合适的样本。
SemanticSimilarityExampleSelector对象,这个对象可以根据语义相似性选择最相关的示例。然后,它创建了一个新的FewShotPromptTemplate对象,这个对象使用了上一步创建的选择器来选择最相关的示例生成提示。
示例选择器example_selector会根据语义的相似度(余弦相似度)找到最相似的示例,也就是“玫瑰”,并用这个示例构建了FewShot模板。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain.prompts.example_selector import SemanticSimilarityExampleSelectorfrom langchain.vectorstores import Chromafrom langchain.embeddings import HuggingFaceEmbeddings1 ,"鲜花类型: {flower_type}\n场合: {occasion}" , "flower_type" , "occasion" ]print (prompt.format (flower_type="红玫瑰" , occasion="爱情" ))format (flower_type="野玫瑰" , occasion="爱情" ))print ("--------------------" )print (result)
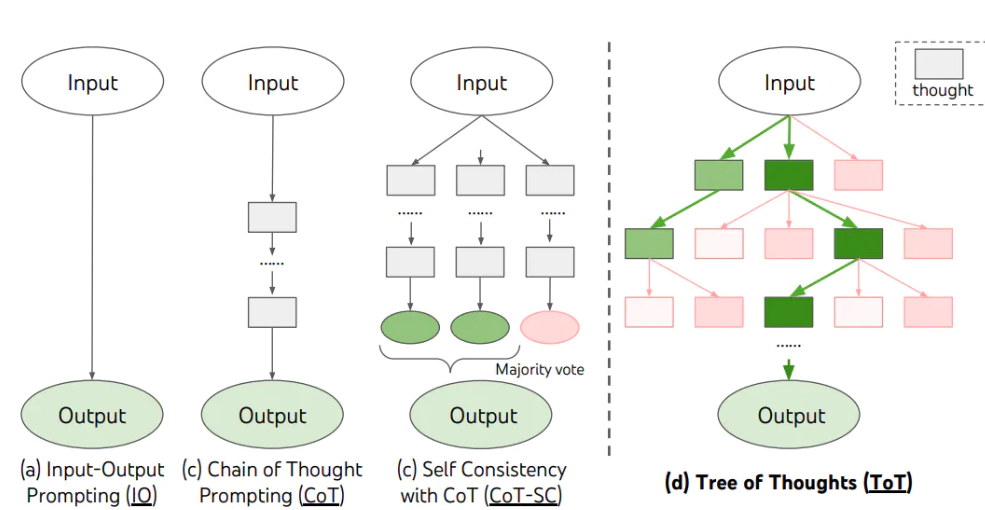
3. CoT CoT这个概念来源于学术界,是谷歌大脑的Jason Wei等人于2022年在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (自我一致性提升了语言模型中的思维链推理能力)》中提出来的概念。它提出,如果生成一系列的中间推理步骤,就能够显著提高大型语言模型进行复杂推理的能力。
3.1 Few-shot CoT 简单的在提示中提供了一些链式思考示例(Chain-of-Thought Prompting),足够大的语言模型的推理能力就能够被增强。简单说,就是给出一两个示例,然后在示例中写清楚推导的过程。
整体上,思维链引导AI从理解问题,到搜索信息,再到制定决策,最后生成销售列表。这种方法不仅使AI的推理过程更加清晰,也使得生成的销售列表更加符合用户的需求。具体到每一个步骤,也可以通过思维链来设计更为详细的提示模板,来引导模型每一步的思考都遵循清晰准确的逻辑。
3.2 Zero-Shot CoT 在Zero-Shot CoT中,你只要简单地告诉模型“让我们***一步步的思考** *(Let’s think step by step) ”,模型就能够给出更好的答案!
3.3 CoT实战 项目需求 :在这个示例中,你正在开发一个AI运营助手,我们要展示AI如何根据用户的需求推理和生成答案。然后,AI根据当前的用户请求进行推理,提供了具体的花卉建议并解释了为什么选择这些建议。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import os"HUGGINGFACEHUB_API_TOKEN" ] = "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" "http_proxy" ] = "http://localhost:7890" "https_proxy" ] = "http://localhost:7890" from langchain_huggingface import HuggingFaceEndpoint"Qwen/Qwen2.5-Coder-32B-Instruct" )"你是一个为花店电商公司工作的AI助手, 你的目标是帮助客户根据他们的喜好做出明智的决定" """ 作为一个为花店电商公司工作的AI助手,我的目标是帮助客户根据他们的喜好做出明智的决定。 我会按部就班的思考,先理解客户的需求,然后考虑各种鲜花的涵义,最后根据这个需求,给出我的推荐。 同时,我也会向客户解释我这样推荐的原因。 示例 1: 人类:我想找一种象征爱情的花。 AI:首先,我理解你正在寻找一种可以象征爱情的花。在许多文化中,红玫瑰被视为爱情的象征,这是因为它们的红色通常与热情和浓烈的感情联系在一起。因此,考虑到这一点,我会推荐红玫瑰。红玫瑰不仅能够象征爱情,同时也可以传达出强烈的感情,这是你在寻找的。 示例 2: 人类:我想要一些独特和奇特的花。 AI:从你的需求中,我理解你想要的是独一无二和引人注目的花朵。兰花是一种非常独特并且颜色鲜艳的花,它们在世界上的许多地方都被视为奢侈品和美的象征。因此,我建议你考虑兰花。选择兰花可以满足你对独特和奇特的要求,而且,兰花的美丽和它们所代表的力量和奢侈也可能会吸引你。 """ from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate"{human_input}" "我想为我的女朋友购买一些花。她喜欢粉色和紫色。你有什么建议吗?" ).to_messages()print (response)
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 baby: 我想为我的女朋友购买一些花。她喜欢粉色和紫色。你有什么建议吗?1. **粉玫瑰和紫玫瑰** :玫瑰是爱情的象征,而粉色和紫色玫瑰分别代表甜美、温柔的爱情和优雅、神秘的爱情。将这两种颜色的玫瑰混合在一起,可以传达出你对她既有温柔又充满神秘感的感情。 2. **紫罗兰** :紫罗兰代表谦逊和纯真,同时也带有神秘的色彩。它们的紫色花瓣非常美丽,可以很好地融入你的主题颜色中。3. **粉绣球花** :绣球花代表纯真和无辜,粉色绣球花则增添了一丝温柔和浪漫的感觉。它们的球形花朵非常独特,能够吸引人的眼球。4. **紫风铃草** :紫风铃草象征着永恒的爱情和友谊,它们的紫色小花在微风中轻轻摇曳,营造出梦幻般的氛围。5. **粉蝴蝶兰** :蝴蝶兰以其优雅的姿态和美丽的花朵而闻名。粉色蝴蝶兰既有高贵的气质,又不失温柔,非常适合用作装饰和礼物。
3.4 Tree of Thought 思维树(Tree of Thoughts,ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
在需要多步骤推理的任务中,引导语言模型搜索一棵由连贯的语言序列(解决问题的中间步骤)组成的思维树,而不是简单地生成一个答案。ToT框架的核心思想是:让模型生成和评估其思维的能力,并将其与搜索算法(如广度优先搜索和深度优先搜索)结合起来,进行系统性地探索和验证。
ToT 框架为每个任务定义具体的思维步骤和每个步骤的候选项数量。例如,要解决一个数学推理任务,先把它分解为3个思维步骤,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 假设一个顾客在鲜花网站上询问:“我想为我的妻子购买一束鲜花,但我不确定应该选择哪种鲜花。她喜欢淡雅的颜色和花香。”