青训营X豆包MarsCode 技术训练营——LangChain实战营
何为LangChain?
LangChain:专为开发基于语言模型的应用而设计的框架,通过LangChain,不仅可以通过API调用如ChatGPT、GPT-4、Llama2等大语言模型,还可以实现更高级功能。
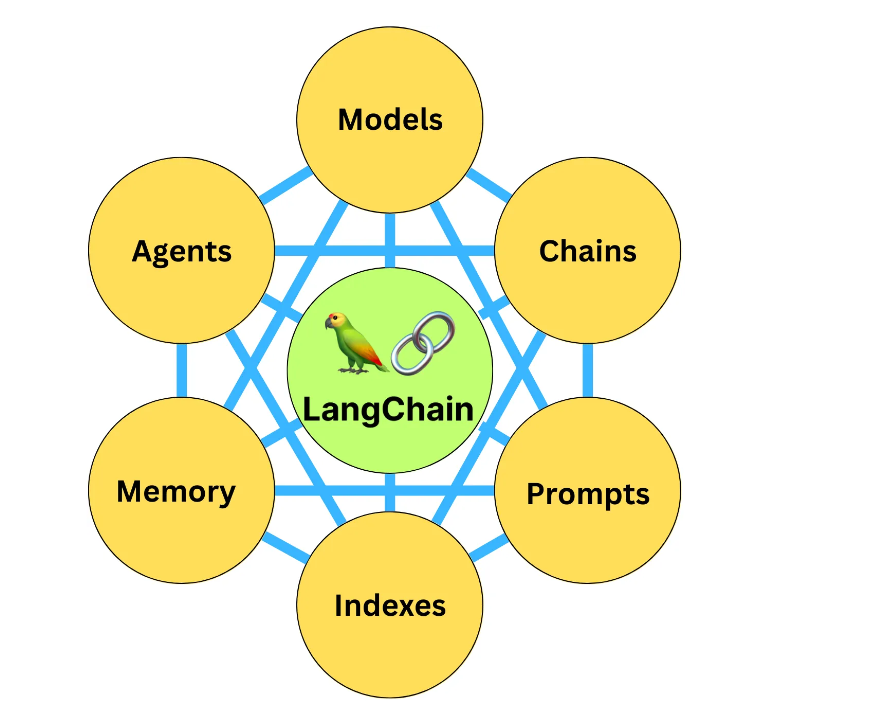
LangChain是一个基于大语言模型(LLMs)用于构建端到端语言模型应用的框架,它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人等。LangChain提供了一系列工具、套件和接口,可以简化创建由LLMs和聊天模型提供支持的应用程序的过程。
学习路线
- 启程篇:LangChain系统的安装流程,以及如何进行快速的入门操作
- 基础篇:深入6大组件
- 应用篇:如何将LangChain组件应用到实际场景中
- 动手篇:如何部署一个鲜花网络电商的人脉工具,并开发一个易速鲜花聊天客服机器人。
两大模型
Chat Model:
gpt-3.5-turbo(也就是ChatGPT)和GPT-4
Text Model:
text-davinci-003(基于GPT3)
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫prompt),返回回答文本(output,也叫response)。但是,它们的调用方式和要求的输入格式是有区别的
调用 Text 模型
1 | |
choices字段是一个列表,因为在某些情况下,你可以要求模型生成多个可能的输出。每个选择都是一个字典,其中包含以下字段:
- text:模型生成的文本。
- finish_reason:模型停止生成的原因,可能的值包括 stop(遇到了停止标记)、length(达到了最大长度)或 temperature(根据设定的温度参数决定停止)。
调用 Chat 模型
- messages:此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
- role:在OpenAI的Chat模型中,system、user和assistant都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
1 | |
通过LangChain调用Text和Chat模型
调用Text模型
1
2
3
4
5
6
7
8
9
10import os
from langchain.llms import OpenAI
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)调用Chat模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)
“易速鲜花”内部员工知识库问答系统
项目介绍:开发一套基于各种内部知识手册的 “Doc-QA” 系统。这个系统将充分利用LangChain框架,处理从员工手册中产生的各种问题。这个问答系统能够理解员工的问题,并基于最新的员工手册,给出精准的答案。
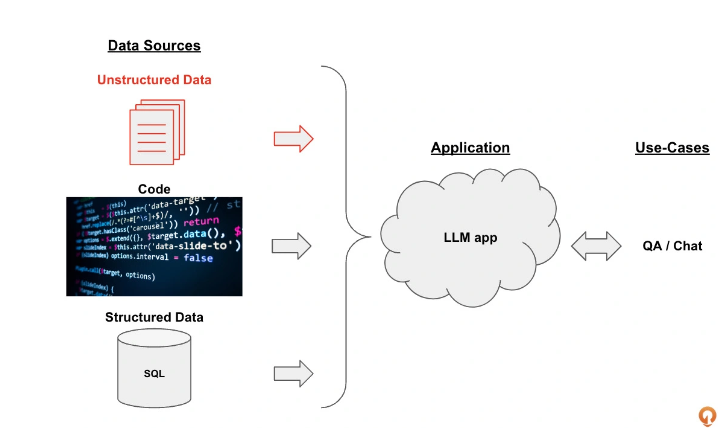
- 数据源:非结构化数据、结构化数据、代码
- 大模型应用:以大模型为逻辑引擎,生成我们所需要的回答。
- 用例:大模型生成的回答可以构建出QA/聊天机器人等系统
核心实现机制:
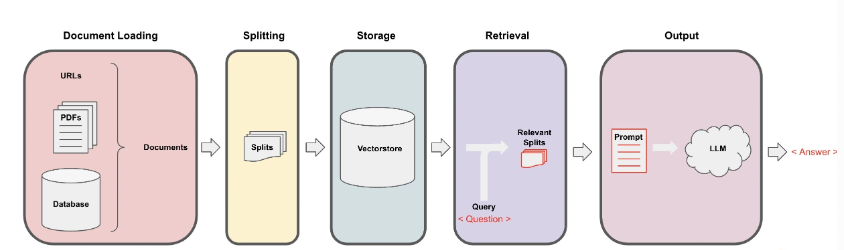
- Loading:文档加载器把Documents 加载为以LangChain能够读取的形式。
- Splitting:文本分割器把Documents 切分为指定大小的分割,我把它们称为“文档块”或者“文档片”。
- Storage::将上一步中分割好的“文档块”以“嵌入”(Embedding)的形式存储到向量数据库(Vector DB)中,形成一个个的“嵌入片”。
- Retrieval:应用程序从存储中检索分割后的文档
- Output:把问题和相似的嵌入片传递给语言模型(LLM),使用包含问题和检索到的分割的提示生成答案。
1. 数据的准备和载入
读取文本(pdf, txt, docx) 到一个列表里面
1 | |
2. 文本的分割
将加载的文本分割成更小的块,以便进行嵌入和向量存储。
1 | |
3. 向量数据库存储
将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中
词嵌入:一个为每个词分配的数字列表
向量数据库:一种专门用于存储和搜索向量形式的数据的数据库,如Pinecone、Chroma和Qdrant。这里我们选择的是开源向量数据库Qdrant。
1 | |
4. 相关信息获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息。
在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
欧氏距离:度量的是绝对距离,它能很好地反映出向量的绝对差异。当我们关心数据的绝对大小,例如在物品推荐系统中,用户的购买量可能反映他们的偏好强度,此时可以考虑使用欧氏距离。同样,在数据集中各个向量的大小相似,且数据分布大致均匀时,使用欧氏距离也比较适合。
余弦相似度:度量的是方向的相似性,它更关心的是两个向量的角度差异,而不是它们的大小差异。在处理文本数据或者其他高维稀疏数据的时候,余弦相似度特别有用。比如在信息检索和文本分类等任务中,文本数据往往被表示为高维的词向量,词向量的方向更能反映其语义相似性,此时可以使用余弦相似度。
建议使用余弦相似度作为度量标准。通过比较问题和答案向量在语义空间中的方向,可以找到与提出的问题最匹配的答案。
1 | |
5. 生成回答
1 | |