基于图片生成诗句(三)
基于图片生成诗句(三)
1 改进措施
改进来源:Rigid Formats Controlled Text Generation (aclanthology.org)
诗句的生成对 句子的韵律,格式,完整性 要求较高。
是否能 指定 诗句的格式模板 从而生成诗句?
基于预定义格式约束的诗句生成
1.1 Contributions
- 一个新的用于严格格式控制文本生成的 预训练和微调的架构
- 制定 符号集 来投稿建模性能、并改进注意力机制
- 收集了 中文和英文的语料集、并设计了 自动评价标准 和 人工评价标准
1.2 任务定义
Input:严格格式$C$
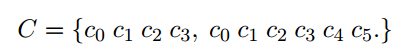
$C$包含 10 个单词 和 2个 标点符号。
$C$是任意的 灵活的!
Output:符合定义格式C的自然语言句子$Y$
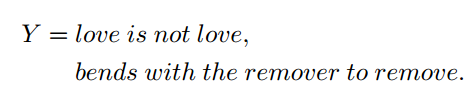
Polishing:基于$Y$重建一个新格式$C^{‘}$,掩盖部分内容
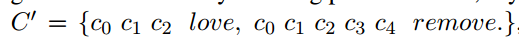
目标:找到一个从$C$到$Y$的映射函数 $Y = G(C)$
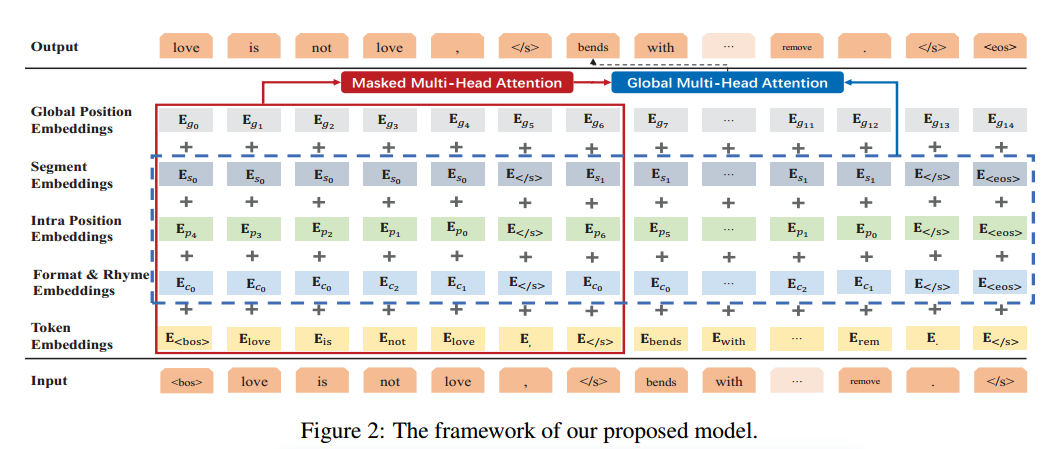
1.3 框架细节
引入符号:
$C = { c_i}$ 控制格式,押韵
$P = {p_i}$ 内部位置符号,每个句子中的tokens的局部位置 , 以提高押韵和句子完整性
$S = {s_i}$ 分段符号,识别句子边界,提高句子完整性
细节:
输入:
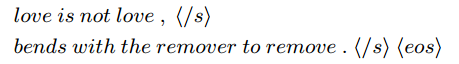
<$/s$>代表子句间的分隔符 eos表示整个句子的结束。
格式和押韵符号:
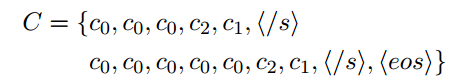
$c_0$表示普通的tokens, $c_1$表示标点符号, $c_2$表示押韵的tokens如love, remove
Intra-Position Symbols:
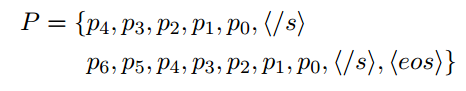
$p_i$表示同一子句中的tokens的局部位置。按照降序排序位置索引符号。
这样,如果$p_0$表示标点符号 那么任意推测 $p_1$表示句子的结束词。
分段符号:
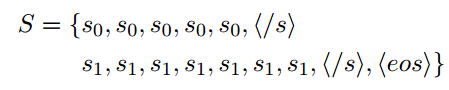
$s_i$表示句子$i$的符号索引。通过定义句子索引特征来增强不同位置的句子之间的相互作用。
1.4 训练
编码输入 :
xs_tpl, xs_seg, xs_pos ——> encode ——> enc (输入序列的编码表示) + src_padding_mask (填充掩码)
初始化自注意力掩码:
1 | |
问题
Q1: 格式控制解释一下?
对于一首词来说,他每个分句的长度可能是5,5,7,5,那么我在最开始的时候就会给定对于这样一个诗句呢,就把它做如下的处理,首先第1点就是给他进行押韵的符号表示。那么什么是押韵的符号表示呢?就是我会在每一个句子句号的前一个字那么它可能是韵脚,那么我就会把这个字呢,就是用符号c2来代替,那么对于一般普通的字呢,那么我就用 c1来表示,那么对于那些标点符号我用c0来表示。第2点呢就是对于句子内部位置的这个字的处理,那么这是怎么处理的呢?我用这个符号p表示,那么对于一个分句从第1个字到最后一个字,那么我是用这样来表示的,如果说它有这个分句长度是5的话,那么第1个字我用p4第2个字就是p3,那我们意思类推一直到p0那么毗邻的。话,它就会是一个标点。然后第3个我做的处理就是对于每个分句之间的这样一个处理,第1个分句我用s0来表示,那么它的每一个字都是s0,那么第2分句就是s1。那么我对于我输入的一个诗句,首先经过这个押韵的表示,再经过再加上我的句子的内部。的表示,那第3个再经过我的啊分句这个sigma表示那么再输入到我的模型中通过多层的符号级的表示那么让我的模型更理解到我这个把我的这个诗句做一个更全面的表征,使他到时候是他最后生成诗句的时候呢,能够学习到我的样本的这样一个押韵韵脚这样一个句子内部的这样一个顺序已知的以及不同分级之间的区别那么。让它生成的时候的更符合我想要求的这样一个格式。
Q2: 用到的数据?如何处理数据?是否要分词?
宋词 (腾讯开源的数据集) + 唐诗(清华AI写诗的比赛上的数据)
词牌名/标题 诗句内容
处理方法:1)提取关键词 (与关键词表交集最多的几个词)2) 把句子中的每个字作为一个单独的token,做以下处理:首先是对每个韵脚用符号c2表示,每个普通的字用c1表示,标点符号用c0表示; 第二个处理时 把不同的分句加以区别,如第一个分句s0, 第二个分句s2, 第三个处理是 对同一个句子内部顺序的表示,假如这个句子长度为5,那么第一个字表示为p_5,最后一个字表示为p_1,结尾的标点为p_0。
不用分词
Q3:如何评价你生成的诗句?
评价一:输出的诗句进入CLIP模型再做编码,与图片计算相似度
评价二:想要评价格式生成是否正确,在n个样本里面,统计有多少个样本的output的格式和原始一致。
评价三:人工评价
Q4:介绍CLIP模型
Q5:介绍Transformer
Q6: 什么是自回归语言模型?
Q7:怎么改进的注意力机制? 那个掩码是什么
Q8:Transformer中涉及的3种掩码?
1)对输入填充的部分,做padding, 那么在做自注意力计算时应该忽略这些填充的位置。填充掩码通常在softmax函数之前应用,奖填充位置的值设置为狠下的负数,让softmax之后其权重为0
2)DECODER的self_atten掩码:在DECODER中,以确保在预测下一个词时,模型只能使用当前位置以前的信息。
3)DECODER的cross-atten掩码:填充了padding,要掩码