CLIP模型原理及实现
CLIP模型
CLIP(Contrastive Language-Image Pre-training)是OpenAI在2021年发布的一种用于图像和文本联合表示学习的模型。CLIP的核心思想是通过对比学习来预训练一个模型,使其能够理解图像和文本之间的关系。
对于一个批次中的每个图像-文本对,模型会计算图像和文本的特征向量,并使用对比损失函数来优化模型参数。对比损失函数的目标是使得匹配的图像-文本对的特征向量尽可能接近,而不匹配的图像-文本对的特征向量尽可能远离。
1 前置知识
1.1 对比学习
侧重于通过对比正反两方面的实例来提取有意义的表征。
分类:
- 监督对比学习:利用标记数据来明确训练模型以区分相似和不相似的实例。
- 自监督对比学习:从未标记的数据中学习表示,而不依赖于显式标签。 SSCL 利用借口任务的设计,从未标记的数据创建正负对。
1.2 图像编码器—VIT
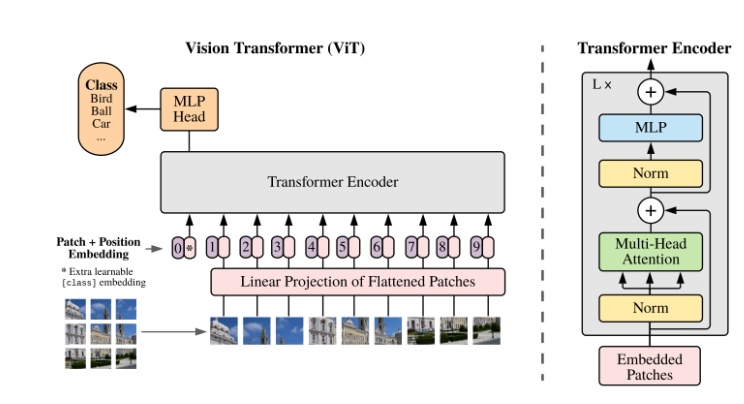
图像特征嵌入模块:
标准的VIT模型对图像的输入尺寸有要求,必须为$224224$.图像输入之后首先是需要进行patch分块,一般设置patch的尺寸为$1616$,那么一共能生成(224/16)*(224/16)=196个patch块。
实现方法:[224,224,3]—(卷积块16*16, s=16,p=0, out_channels=768)—>[14,14,768]—(展平)—>[196, 768]
Transformer Encoder:LN + Multi-Head + MLP
LayerNom:对每一层的样本做归一化,不易受到batch_size的影响,能处理可变长的序列数据。且有助于在深层网络中保持训练的稳定性。
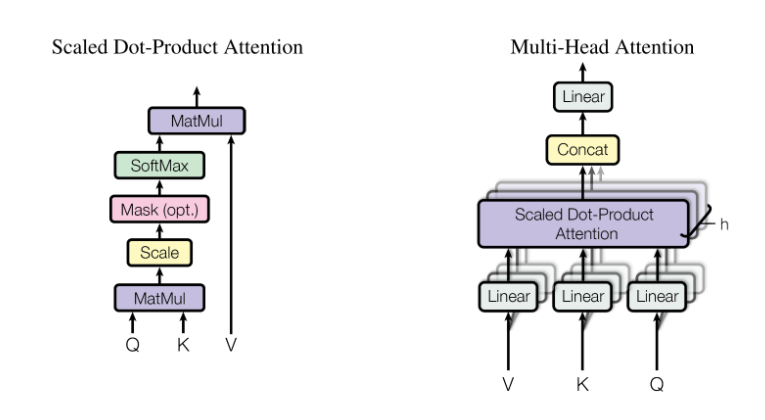
Multi-Head Attention:
自注意力:$soft(\frac{X W^Q (X W^K)^T}{\sqrt(d_k)})XW^V$
多头注意力机制能够联合来自不同head部分学习到的信息。根据使用的head的数目h进一步把得到的$W^Q, W^K, W^V$均分成h份,之后再做concat。
FFN:
norm——> linear ——> gelu ——> dropout——> linear ——> dropout
(为什么是gelu函数? RELU $max(0,x)$虽然非线性,但是在x=0不可导,gelu:$x \phi(x), \phi(x)$是N(0,1)的CDF,其在x=0处可导)
MLP分类:使用非线性激活函数去做分类的预测
1.3 文本编码器—BERT
2 模型
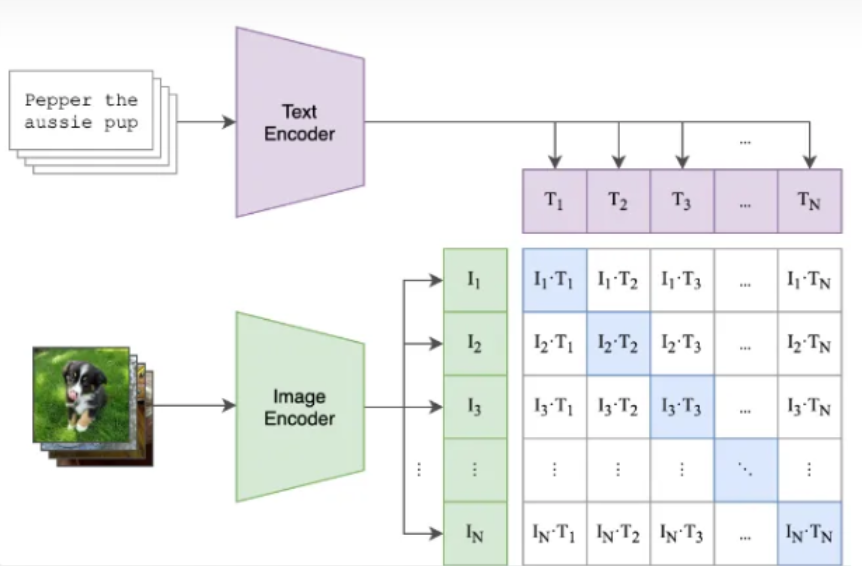
特征提取:
Imag ——> (Imag_Encoder) ——> Imag_Feature [n, d_i]
Text ——> (Text Encoder ) ——> Text Feature [n, d_t]
线性投影到一个特征空间:
Imag_Feature ——> (Projection) ——> Image_projection [n, d_out]
Text_Feature ——> (Projection) ——> Text_projection [n, d_out]
计算余弦相似度 :logits = np.dot()…
计算损失:损失设计包括两个方向:从图像到文本和从文本到图像
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
被问过的问题
Q1: 为什么CLIP模型每个输入被tokenizer成 77个 token?
A:CLIP模型在处理文本输入时,将每个输入限制为最多77个token,这是因为模型在设计时设置了一个固定长度的上下文窗口。。CLIP模型使用了Byte-Pair Encoding (BPE)分词器,这种方法会将常见的词作为单个token,但不常见的词会被拆分成多个token。
Q2:多头注意力机制里面为什么要除以$sqrt(d_k)$?
A:$d_k$指的是Q和K的维度,也就是隐藏层的维度。在进行dot-product操作时,$d_k$过大会导致数值变得很大,softmax后的值分散很大,模型的方差会很大,不利于模型的训练。
Q3:为什么残差连接能防止梯度消失?
A:梯度消失是指在深层网络中,梯度在反向传播过程中逐渐变小,以至于网络的权重无法得到有效更新的现象。在反向传播过程中,由于跳跃连接的存在,梯度可以直接流向网络的早期层,保持了梯度的规模,使得深层网络的训练变得更加稳定。上层梯度* (1+ 这层函数对参数的偏导数 )
Q4:VIT中的FFN的作用?
A:FFN通常时两个MLP+一个非线性激活构成,在前面的多头注意力中只有dot-product操作,除去softmax后,不包含非线性操作,所以在FFN中涌入非线性变换,能够提升模型的表征能力,从而捕获更复杂的特征。
Q5:VIT中dropout的作用?
Dropout是一种正则化技术,在训练过程中随机使得一些神经元失效,防止模型过度依赖于特定的输入特征,避免过拟合。VIT中使用的时DropPath,也叫Stochastic Depth, 他时随机丢弃整个网络层或者层的一部分,过随机地将网络中的某些路径的输出置为零,模拟了网络的不同子网络的组合。