文生图的各种模型
各种文生图的模型
DALL-E
参数量:120亿
基于 dVAE
训练:
- 训练一个dVAE, 训练dVAE编码器和dVAE解码器
- 将文本编码和图片token进行拼接,训练一个自回归transformer来建模文本和图片的联合分布
训练目标:最大化ELBO
GLIDE
参数量:35亿
把 指导扩散应用于文本生成图像的问题。
使用文本编码器以自然语言描述为条件,然后比较了两种指导扩散模型至文本 prompt 的方法:CLIP 指导和无分类器指导。无分类器指导能够产生更高质量的图像。
DALL-E2
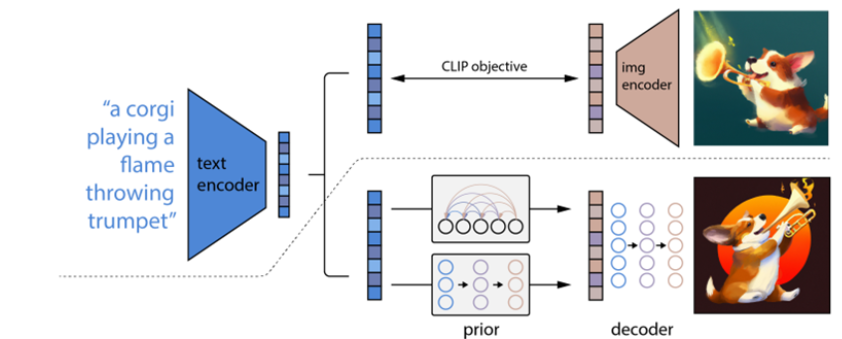
虚线上方为CLIP
虚线之下是文本到图像生成的改成。
一个CLIP text embedding输入到autoregressive或者扩散模型(prior部分)来生成一个image embedding,然后这个embedding输入到扩散模型decoder,生成最终的图像。
训练方法:
训练数据对$(x,y)$, $x$指图片,$y$指文字描述
对于$x$,通过CLIP模型生成imag embedding$z_i$
prior: 基于文本 生成imag embedding
decoder: 基于prior生成的imag embedding来生成图像
Imagen
使用了一个文字转图片的diffusion模型,然后使用了2个超分diffusion模型。
Stable Diffusion
模型latent diffusion models (LDMs)是两阶段的。第一部分就是下面左半部分(红色),对图片进行压缩,将图片压缩为隐变量表示(latent),这样可以减少计算复杂度;第二部分还是扩散模型(diffusion与denoising),中间绿色部分。此外引入了cross-attention机制,下图右半部分,方便文本或者图片草稿图等对扩散模型进行施加影响,从而生成我们想要的图片,比如根据文本生成我们想要的图片。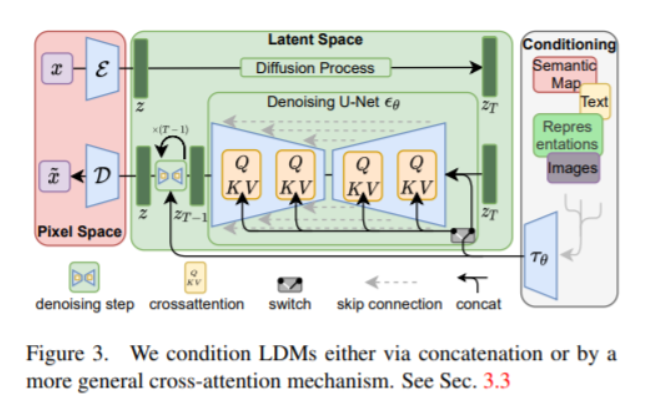
文生图的各种模型
https://wendyflv.github.io/2024/09/06/文生图的各种模型/