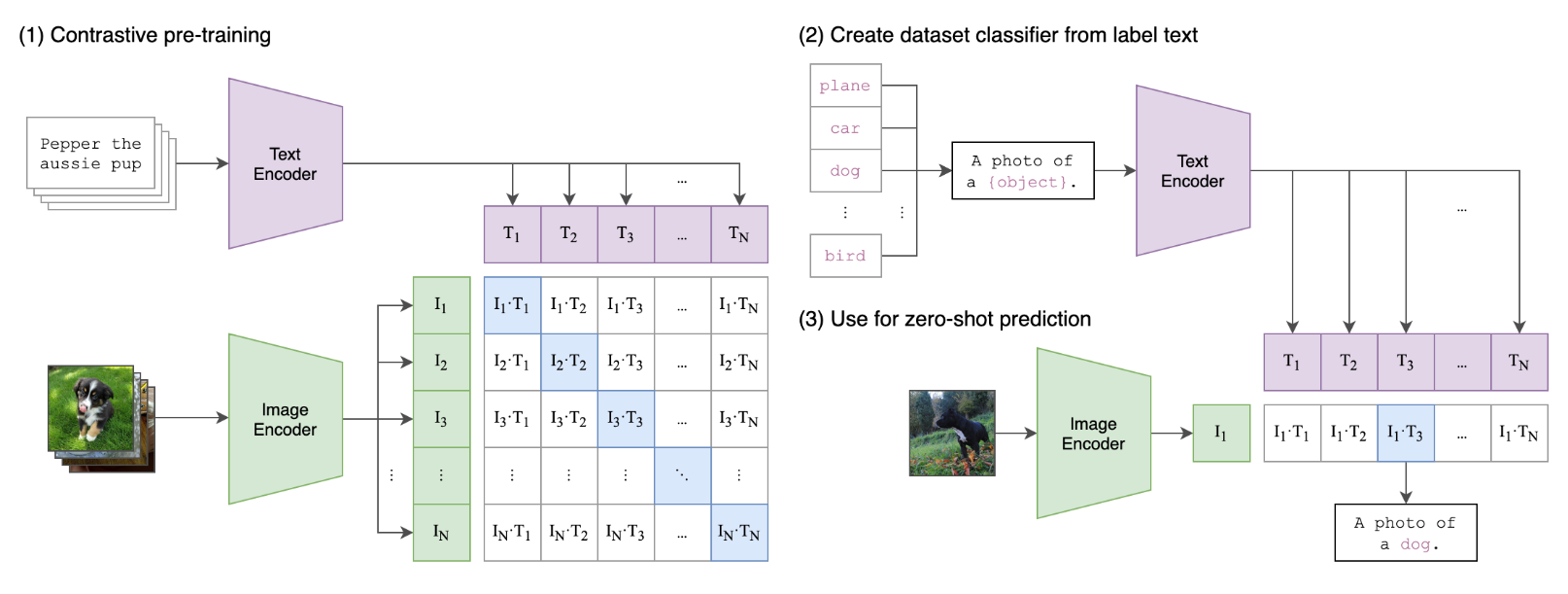
基于图片生成诗句(二) 一、CLIP模型 该模型的核心思想是使用大量图像和文本的配对数据进行预训练,一学习图像和文本之间的对齐关系。CLIP包含2个模态:文本和视觉模态。
Text Encoder: 用于把文本转成低维向量表示
Image Encoder:用于把图像转成类似向量表示
在预测阶段,计算文本和图像向量之间的余弦相似度 来生成预测。
1. Components
1.1 Image Encoder
架构一:基于ResNet50, 根据ResNetD改进,还将全局平均池化层 替换为注意力池化机制 。
架构二:基于VIT
1.2 Text Encoder 文本编辑器使用Transformer架构,并在此基础上根据Radford模型进行了架构修改。
2. Method 2.1 数据集 文章构建了一个新的数据集,其中包含4亿对(图像、文本),这些数据集来自互联网上各种公开可用的资源。为了尝试覆盖尽可能广泛的视觉概念集,文中将搜索(图像,文本)对作为构建过程的一部分,其文本包含500,000个查询集中的一个。
2.2 预训练方法 给定一批N对的(img, text)对,CLIP来训练这$N \times N$的组合中哪几对会实际发生。最大化N对真实嵌入对的余弦相似度,最小化剩下$N^2 - N$对错误嵌入的余弦相似度。在这些相似性得分上优化对称交叉熵损失。
2.3 训练方法 CLIP预训练时训练的Text Encoder和Image Encoder在大量数据上能正确配对图像和文本。 然后, 使用这种方法把CLIP变成zero-shot分类器,把数据集种所有类转为文本,’a photo of a {object}’, 来预测CLIP估计的标题类与给定图像的最佳配对。
二、本项目为什么要引入CLIP 在之前 版本1(基于图片生成古诗 - Wendyflv的博客 )中,我基于Resnet在Cifar100数据上进行图像分类,把图像的标签局限于100个标签(且关键词的对应还是自己人为设定的),尽管之后使用了word2vec进行补救充沛关键词,但是扩充的关键词只是基于原图像的标签,并不能发掘更多的特征。如果考虑使用CLIP模型,生成古诗意象关键词向量和图像向量,给图像匹配关键词,能提高模型的泛化性能。
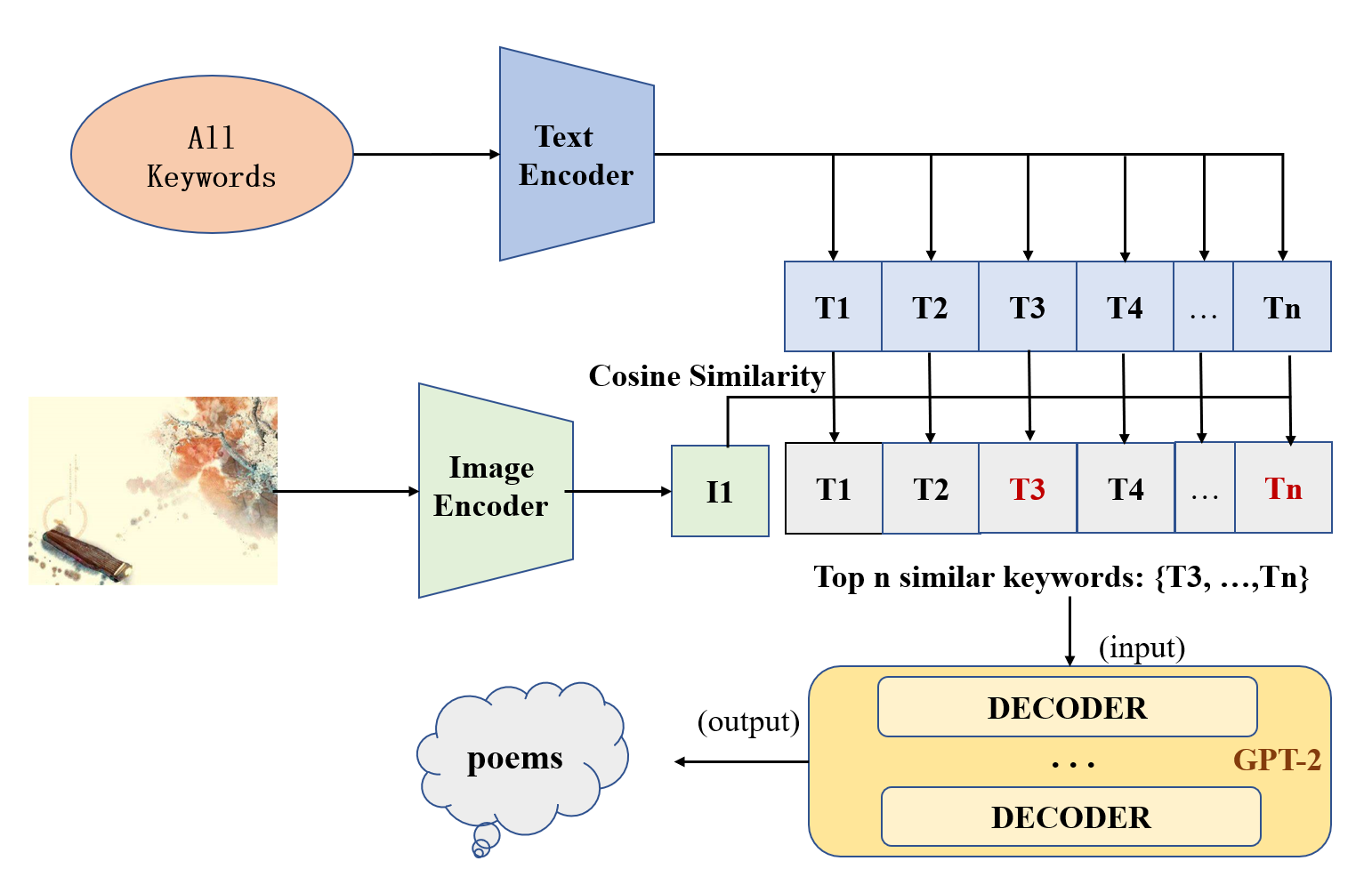
先搜集一个关键词数据集(keyword.txt),然后使用CLIP对图像和所有关键词进行编码,计算它们之间的相似度,取相似度最高的K个关键词,然后放置于语言模型进行生成.
三、项目架构
1. CLIP模型 直接调用中文CLIP模型
下面举个使用Chinese_CLIP对给定的一副图像和多个关键词匹配相似度的例子
img——>(CLIP)——>img_feature [1 × 512]
key_words ——>(CLIP)——> text_features [n × 512]
img , key_words——> cosine_similariy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from transformers import ChineseCLIPProcessor, ChineseCLIPModelfrom PIL import Imageimport torch"./Chinese_CLIP" )"./Chinese_CLIP" )open ('D:/NLP/CLIPForPoems/Image2Poem/datasets/images/chun.jpg' )"pt" )print (image_features.shape)'余晖' , '樱花' , '春色' ,'晚霞' ,'夏日' , '沙漠' , '旅人' ]for keyword in key_words:"pt" )def cosine_similarity (x, y ):return torch.sum (x * y) / (torch.sqrt(torch.sum (pow (x, 2 ))) * torch.sqrt(torch.sum (pow (y, 2 ))))0 for text_feature in text_features:print (key_words[i], similar)1
结果:下面输出了每个关键词与图像的相似度([0,1])。
余晖 tensor(0.4195, grad_fn=)))))))
2. 诗句生成模型 之前自己训练的效果太差了,改用T5模型在古诗词上微调。
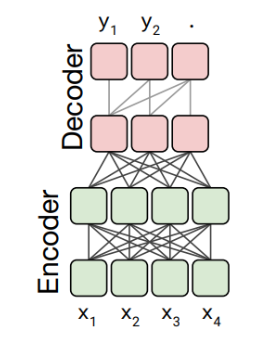
T5模型采用的是基于Transformer的Encoder-Decoder结构。
下面使用(孟子中文T5 )微调一个诗句生成模型。
2.1 数据预处理 数据来源:中国古典诗歌匹配数据集
把数据处理成 输入:关键词+诗句的 输出:诗句
例如:
x = [CLS]关键词:春日 细雨 余晖[EOS] 春山新雨后[EOS] 天气晚来秋[EOS] 明月松间照[EOS]
y = [CLS]清泉石上流[EOS]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 with open ("./datasets/CCPC/ccpc_train_v1.0.json" , "r" , encoding="utf-8" ) as f:sum (1 for _ in open ("./datasets/CCPC/ccpc_train_v1.0.json" , "r" ,encoding="utf-8" ))for line in tqdm(f, desc="Loading Data" , total=total_lines):"keywords" ].strip()"content" ].strip().split("|" )for i in range (len (poems)):if i ==0 :"关键词:" + keywordselse : x = "关键词:" + keywords + "EOS" "EOS" .join(poems[:i]) + "EOS" , poems[i] + "EOS" )print (line)"EOS" .join(poems[:i]) + "EOS" , poems[i] + "EOS" ))len (lines)break
构造一个batch输入和输出:确定输入长度,输出长度。对不满足的文本做填充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def __getitem__ (item ):1 ) * batch_size]max ([ len ( s[0 ].replace(" " ,"" ).replace("EOS" , "" )) for s in data]) + 6 max ([ len (s[1 ].replace(" " ,"" ).replace("EOS" , "" )) for s in data]) +3 print ("input_len:" , input_len)print ("output_len: " , output_len)for i in range (batch_size):0 ])1 for _ in range (len (x))]0 for _ in range (input_len - len (x))]for _ in range (input_len - len (x))])1 ])1 for _ in range (len (y))]0 for _ in range (output_len - len (y))]for _ in range (output_len - len (y))])print (x)print (tokenizer.decode(x))print (y)print (tokenizer.decode(y))print (atten_x)print (atten_y)break
2.2 T5模型 简单输出一下模型的结构看看:
input——>[Embedding Layer]——>Encoder[n × T5Block ] ——>Decoder[n ×T5Block ] ——>LM Head——> output
对于Encoder的一个T5Block:包括一个自注意力机制,前馈网络 和 层归一化。
对于Decoder的一个T5Block:包括:字注意力机制,跨注意力机制(关注解码器的输出), 前馈网络 和 层归一化
2.3 训练