基于解耦注意力的GraphTransformer
基于解耦注意力的GraphTransformer
本项目致力于改进单目3D人体形状和姿态估计技术,基于 SMPL 模型实现高效和精准的姿态预测。项目的核心创新在于对VIT架构的优化,通过解耦注意力机制,显著降低了特征计算的复杂度,将计算成本从二次计算减少到线性层面。此外,我们在VIT中引入了图卷积网络(GCN),以对人体关节表示进行深度特征提取,增强了模型对空间结构信息的捕捉能力,从而进一步优化了目标表示。实验结果表明,我们提出的方法在多个基准上明显优于以前最先进的方法,包括 Human3.6M、3DPW数据集。
GraphTransformer
解耦的注意力机制
传统的方法都是将 feat + target拼接在一起做self-attention。
$h(Q,K,V) = softmax(\frac{(QW_q)(KW_k)^T}{\sqrt d})(VW_v)$
这样会造成对$l_F$的二次计算
如果把$h_{self}(T||F)$ 改成$h_{self}(h_{cross}(T,F))$ 将会避免对$l_F$的二次计算。
在一个trans_unit中:
1 | |
Graphformer
对于输入的特征和目标表示,经过如下模块。
input -> (Norm) -> (Attention) -> (Linear) -> (Drop) -> (Add) -> (GCN)
-> (Norm) -> (Linear) -> (Gelu) -> (Linear) -> (Drop) -> (Add) -> output
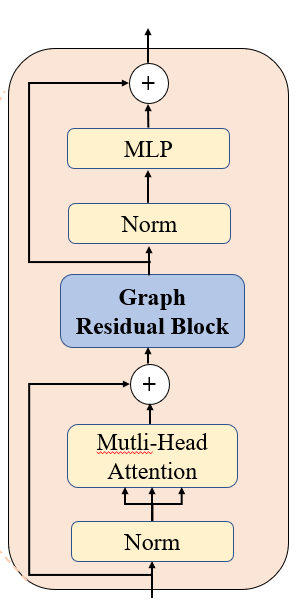
Graph Residual Block
训练:20min/次
测试:15min次
基于解耦注意力的GraphTransformer
https://wendyflv.github.io/2024/08/24/基于解耦注意力的GraphTransformer/