spark
spark
框架模块
spark core:核心RDD
spark sql:针对结构化数据,本身针对离线计算。
spark streaming: 在core基础上,流式计算
运行模式
本地模式:local,以一个独立进程,通过其内部多个线程模拟spark(开发,测试)
standalone:集群,各个角色以独立进程的形式存在
YARN:集群,角色运行在YARN的容器内,
Kubernets:在Kubernets容器内
云服务:在云平台上运行
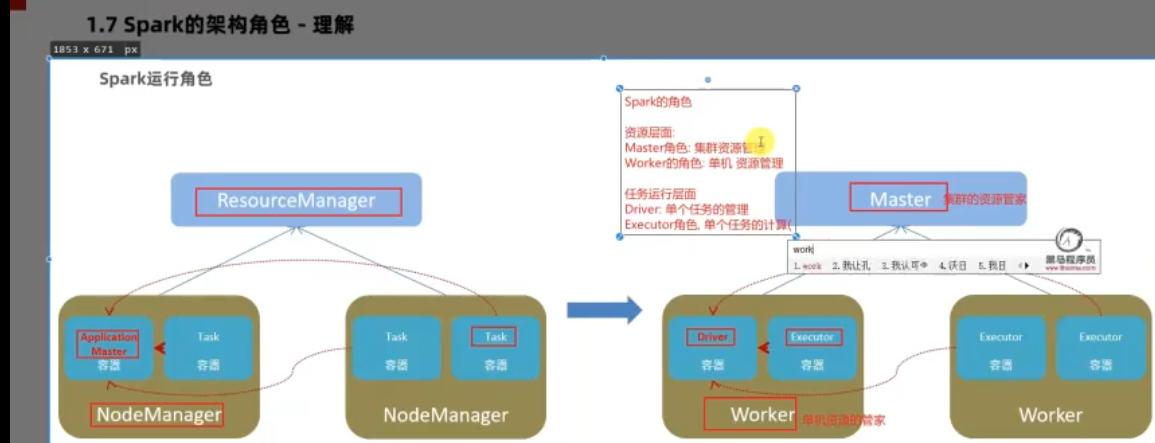
架构角色
YARN
resoumanger:集群管理
nodemanger:单机管理
applicationmaster:单任务管理者
task:单任务执行
spark
master:集群资源管家
worker:单机资源管家
Driver:管理单任务 (在local模式在,既管理又干活)
Executor:运行单任务
local模式
local[N] 指定N个线程模拟
local[*] 对线程数无限制,根据cpu的cores设定

sparkcount
创建sparkconf对象
通过sparkcontext创建对象
1 | |
读文件
读本地的文件
1
2file_rdd = sc.textFile("./data/input/word.tx")
# "file:///tmp/pycharm_project_846/data/input/word.txt" linux上文件读HDFS上的文件
1
file_rdd = sc.textFile("hdfs://node1:8020/input/word.txt")
wordcount原理
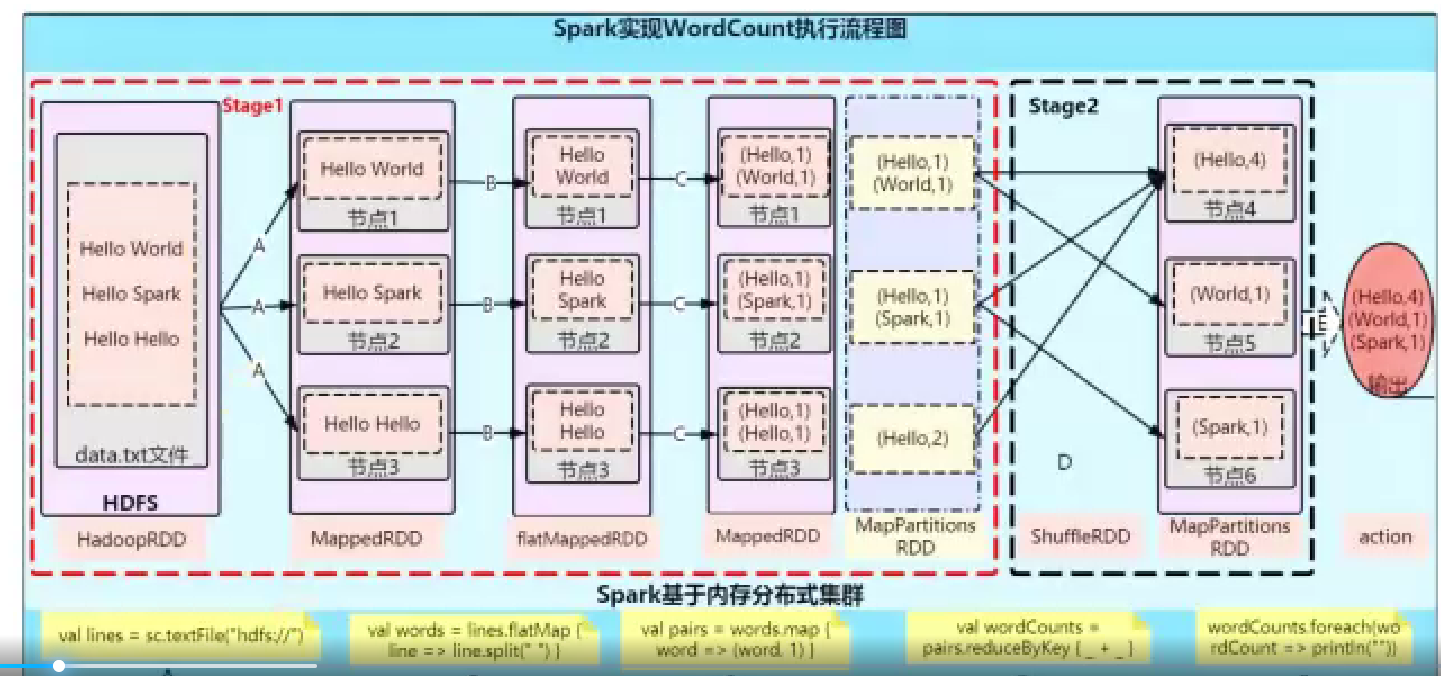
RDD
简介
RDD:弹性(数据讯息再内存或磁盘中)分布式(跨进程存储)数据集合,分布式框架下的统一数据抽象对象
特性:有分区;计算方法都会作用再每一个分片上;RDD之间又相互依赖关系;KV型RDD可以有分区器;分区数据的读取尽量靠近数据所在服务器
一份RDD本质分成了多个分区:

KV型RDD:RDD内存存储的数据式二元元组(“hadoop”,3)(“hadoop”,1)(“flink”,3)
默认分区器:hash分区器
编程操作
程序入口:sparkcontext对象
RDD创建:
并行化集合创建(本地转分布式RDD);
1
2
3
4
5
6
7conf = SparkConf().setMaster("local[*]").setAppName("test")
sc = SparkContext(conf=conf)
# 本地转分布式RDD对象
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
print("分区:",rdd.getNumPartitions())
# 把RDD每个分区的对象collect到driver
print("RDD内容:", rdd.collect())读取外部文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 读取本地文件
file_rdd = sc.textFile("../../data/input/word.txt")
print(file_rdd.getNumPartitions())
print(file_rdd.collect())
file_rdd2 = sc.textFile("../../data/input/word.txt",3)
print(file_rdd2.getNumPartitions())
file_rdd3 = sc.textFile("../../data/input/word.txt", 100)
print(file_rdd3.getNumPartitions())
# 读取HDFS
file_rdd4 = sc.textFile("hdfs://node1:8020/input/word.txt")
print(file_rdd4.collect())
# 针对小文件
rdd = sc.wholeTextFiles("../../data/input/tiny_files")
print(rdd.map(lambda x:x[1]).collect())
RDD算子:分布式集合上的API
Transformation转换算子 RDD——>RDD
构建执行计划,对RDD迭代,无Action不干活
map算子(接收处理函数)
1
print(rdd.map(lambda x: x*10).collect())flatmap算子(先map 再解除嵌套)
1
2
3rdd = sc.parallelize(["hadoop spark map", "spark flink", "hadoop spark"])
print(rdd.map(lambda x: (x.split(" "))).collect())
print(rdd.flatMap(lambda x: (x.split(" "))).collect())reducebykey (自动按照key分组,完成组内数据的聚合)
1
2
3# 传入的参数只是对value
rdd = sc.parallelize([['a',1], ['b',1], ['c',1], ['a',2]])
print(rdd.reduceByKey(lambda a,b: a+b).collect())mapvalues 只针对value的map算子
1
2rdd = sc.parallelize([('a',1), ('b',1), ('c',1)])
print(rdd.mapValues(lambda value: value*10).collect())- groupby (确定按照k还是v分组)
1
2
3rdd = sc.parallelize([('a',1), ('b',1), ('c',1),('a',4), ('b',4), ('c',6)])
print(rdd.groupBy(lambda x:x[0]).map(lambda x:(x[0], list(x[1]))).collect())- Filter (过滤数据,结果为True的保留)
1
2
3rdd = sc.parallelize([1,2,3,4,5,6])
result = rdd.filter(lambda x: x %2 == 1)
print(result.collect())- distinct(去重)
1
2rdd = sc.parallelize([1, 1, 2, 2, 2, 3, 4, 5, 6])
print(rdd.distinct().collect())union(2个RDD合并成一个)
1
2
3
4
5rdd = sc.parallelize([1, 1, 2, 2, 2, 3, 4, 5, 6])
rdd2 = sc.parallelize(['a','v'])
rdd3 = rdd.union(rdd2)
print(rdd3.collect())join (对两个RDD执行JOIN操作 只用于二元组, 内连接,左外,右外)
1
2
3
4
5
6
7
8
9rdd = sc.parallelize([(1001, 'zhangsan'), (1002, 'lisi'),
(1003, 'wangwu'), (1004, 'laoliu')]
)
rdd2 = sc.parallelize([(1001, '科技部'), (1002,'教育部')])
# 按照key关联
rdd3 = rdd.join(rdd2)
print(rdd3.collect())
print(rdd.leftOuterJoin(rdd2).collect())
print(rdd.rightOuterJoin(rdd2).collect())intersection (求两个RDD的交集)
rdd.intersection(rdd2)
glom (将RDD数据加上嵌套, 这个嵌套按照分区处理)
rdd.glom().collect()
groupbykey(针对KV型,自动按照Key分组)
sortby(对RDD数据进行排序)
rdd.sortby(func, ascending=True)1
2
3rdd = sc.parallelize([('a', 1), ('a',3), ('c', 5), ('b', 2)])
print(rdd.sortBy(lambda x :x[0], ascending=True, numPartitions=1).collect())sortbykey(对KV型的,按Key排序)
sortbykey(ascending=True, numparttions, func)
func: 再排序前对数据key处理
mappartitions (对每个分区只有一次IO)结果与map无差异
func里面传入的是迭代器对象
partitionby (自定义分区操作)
repartition(对RDD分区重新分区,仅改变数量,不约定新分区规则)
案例:对订单数据,提取背景的数据,组合北京合商品类别进行输出,并对结果进行去重,得到北京售卖的商品类别信息
1
2
3
4
5
6
7
8
9
10rdd = sc.textFile("../../data/input/order.text")
file_rdd = rdd.flatMap(lambda line: line.split("|"))
dict_rdd = file_rdd.map(lambda json_dir : json.loads(json_dir))
# 过滤数据
bj_rdd = dict_rdd.filter(lambda d : d['areaName']=='北京')
# 组合北京合商品类型
ctg_rdd = bj_rdd.map(lambda d : d['areaName'] + '-' + d['category'])
# 去重
res_rdd = ctg_rdd.distinct()
print(res_rdd.collect())Action算子 RDD——> not RDD
countBykey(对key进行计数)
collect(把RDD各个分区数据收集到driver,形成一个List对象)
reduce (对RDD数据集按照传入逻辑聚合)
fold (带有初始值的聚合)
rdd.fold(10, lambda a,b:a+b) 初始值会在分区内 和 分区键聚合 都用到
first (取出RDD的第一个元素)
take (取RDD的前N个元素) 返回list
top (对RDD结果进行降序排序,取前N个)
count (RDD中数据量)
takesample(随机抽样RDD数据)
takesample(True, 采样数,随机数种子) True:允许重复取一个数字
takeordered 对RDD排序取前N个
takeordered(前N个, 对排序数据更改) 默认升序
foreach (对每个元素进行你想要的操作) +func 由excutor直接输出
saveastextfile (将RDD数据写入文件)由excutor直接输出
mappartitions ()
foreachpartiton (一次处理一整个分区的数据)
流水线的开关
RDD缓存
RDD是过程数据,老旧没用的会从内存清理
RDD缓存API:rdd.cache() rdd.persist()
Spark案例练习
任务:搜索关键词统计,用户搜索点击统计,搜索时间段统计
广播变量
进程内资源共享,一个进程里面的数据发了一份即可
broadcast = sc.broadcast(原数据)
value = broadcast.value
本地集合对象和分布式对象操作时需要使用广播变量避免多次网络IO
累加器:
ac = sc.accumalate(0)
能把每个分区的数据反映到全局变量中
Spark SQL
- 概述
Spark的用于处理结构化数据的module
pandas: dataframe 二维表,单机集合
sparkcore:RDD 无标准数据结构,分布式集合
sparksql:datatframe 二维表,分布式集合
dataset:用于java和scala
dataframe: 用于python java scala
- sparkSession对象:sparksql的入口对象,也可以用于RDD编程
- dataframe组成:structtype描述表结构。structfield描述一个列的信息, row对象记录一行数据, column记录一列列数据并包含列的信息
dataframe代码构建
基于RDD
1
2
3
4
5
6
7
8
9
10
11
12
13rdd = sc.textFile("../data/input/sql/people.txt").\
map(lambda line: line.split(",")).\
map(lambda line: (line[0], int(line[1])))
# 参数1:rdd 参数2:列名
df = spark.createDataFrame(rdd, schema=['name', 'age'] )
df.printSchema()
# n:展示多少数据 truncate:是否对数据进行截断
df.show(20, truncate=False)
df.createOrReplaceTempView("people")
spark.sql("select * from people where age > 30").show()读取外部数据:parquet:SPARK的列式存储文件格式
编程操作:
DSL语法 df.where().limit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# df.select(["id", "subject"]).show()
# df.select("subject", "score").show()
# df.select(id_column, subject_column).show()
# # filter
# df.filter("score < 99").show()
# df.filter(df["score"] < 99).show()
#
# # where
# df.where("score < 99").show()
# df.where(df["score"] < 99).show()
# groupby 分组 返回值groupeddata,不是df了 得接上聚合mean, max,count
df.groupBy("subject").count().show()
df.groupBy(df["subject"]).count().show()SQL语法 spark.sql()
1
2
3
4
5
6
7
8df.createTempView("score")
df.createOrReplaceTempView("score_1")
df.createGlobalTempView("score_2")
spark.sql("select subject, count(*) from score group by subject").show()
spark.sql("select subject, count(*) from score_1 group by subject").show()
spark.sql("select subject, count(*) from global_temp.score_2 group by subject").show()
wordcount案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15rdd = sc.textFile("../data/input/word.txt").\
flatMap(lambda x: x.split(" ")).\
map(lambda x: [x])
df = rdd.toDF(["word"])
df.createTempView("words")
spark.sql("select word, count(*) as cnt from words group by word order by cnt desc ").show()
df =spark.read.format("text").load("../data/input/word.txt")
# withcolumn:对已存在的列做新操作,返回一个新列
df2 = df.withColumn("value", F.explode(F.split(df['value'], " ")))
df2.groupBy("value").count().\
withColumnRenamed("value", "word").\
withColumnRenamed("count", "cnt").\
orderBy("cnt", ascending=False).show()电影评分案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40schema= StructType().add("user_id", StringType(), nullable=True).add("movie_id", IntegerType(), nullable=True).add("rank", IntegerType(), nullable=True).add("ts", StringType(), nullable=True)
df = spark.read.format("csv").option("header", False).option("sep", "\t").option("encoding", "utf-8").schema(schema).load("../data/input/sql/u.data")
df.groupBy("user_id").avg("rank").withColumnRenamed('avg(rank)','avg_rank').\
withColumn('avg_rank', F.round('avg_rank', 2)).\
orderBy('avg_rank', ascending=False).show()
df.createTempView("movie")
spark.sql("select movie_id, round(avg(rank), 2) as avg_rank from movie group by movie_id order by avg_rank").show()
# 查询大于平均分电影数量
num = df.filter(df["rank"] > df.select(F.avg(df["rank"])).first()['avg(rank)']).count()
print(num)
# 查询大于3分电影中打分最多次的用户,其平均分
usr_id = df.where(df["rank"]> 3).groupBy("user_id").count().withColumnRenamed('count', 'cnt').\
orderBy('cnt', ascending=False).limit(1).first()["user_id"]
df.filter(df["user_id"]==usr_id).select(F.round(F.avg(df["rank"]),2)).show()
# 查询每个用户的最低和最高打分
df.groupBy('user_id').\
agg(
F.round( F.avg("rank"), 2).alias('avg_rank'),
F.min('rank').alias('min_rank'),
F.max('rank').alias('max_rank')
).show()
# 查询评分超过100次的电影的平均分排名top10
df.groupBy('movie_id'). agg(
F.count('movie_id').alias('cnt'),
F.round(F.avg('rank'),2).alias('avg_rank')
).where('cnt > 100' ).orderBy('avg_rank', ascending=False).\
limit(10).show()
# agg : 是groupeddata对象的api,在里面可以写多个聚合
# alias: 是column对象api,对列改名
# withcolumnRename: 是dataframe的api
# orderby:dataframe的api
# first: dataframe的API 返回第一个row对象,不再是dfshuffle分区数目设置
1
2
3
4spark = SparkSession.builder.appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", "2").\
getOrCreate()数据清洗API