预训练模型
预训练模型
预训练简介
预训练:通过子监督学习从大规模数据里获取与具体任务无关的预训练模型的过程。
预训练任务:
掩码语言模型(编码器):将一些位置的token替换成特殊的[MASK]字符,预测这些被替换的字符

只计算掩码部分的loss,其余部分不计算loss
因果语言模型(解码器):输入完整序列,基于上文预测当前token

eos代表句子结束
序列到序列模型:编码器解码器方式,预测部分放到解码器里面
只计算解码器的loss,不计算解码器部分
文本摘要
文本摘要:输入长文本,将长文本转成简短的摘要
任务类别:单文档单语言摘要
评价指标:Rouge-1(基于1-gram) Rouge-2(基于2-gram) Rouge-L(基于LCS)
| 原始文本 | 1-gram | 2-gram |
|---|---|---|
| 今天不错 | 今 天 不 错 | 今天 天不 不错 |
| 今天太阳不错 | 今 天 太 阳 不 错 | 今天 天太 太阳 阳不 不错 |
Rouge-1 P = 4/4 R=4/6 F = 2PR(P+R)
Rouge-2 P = 2/3 R=2/5
LCS(最长公共子序列) P = 4/4 R=4/6
数据处理
input和labels分开处理,labels最后一定要有eos_token
labels不仅是标签,还是解码器的输入
数据集:
对话机器人
参数微调fine-tuning
beat-fit
只对bias求梯度,其他的参数冻结
prompt-Tuning
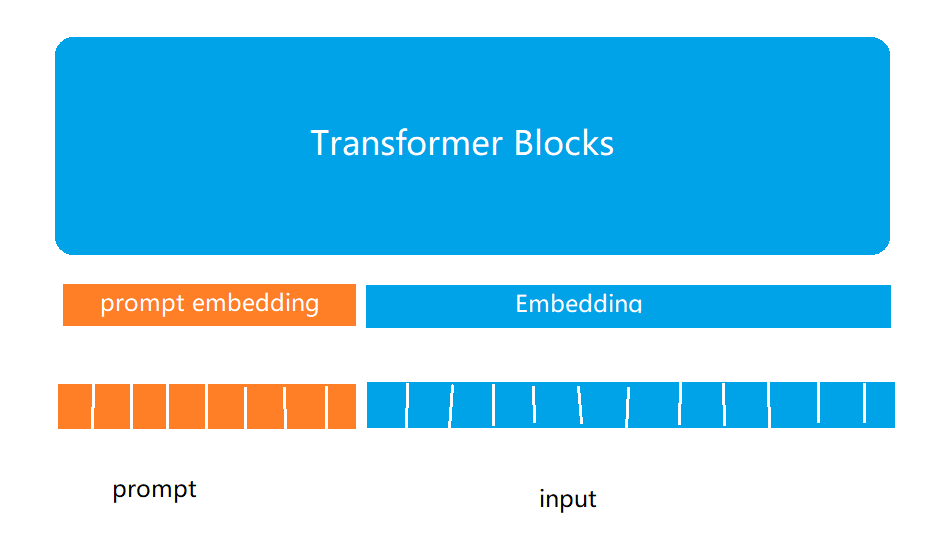
冻结主模型所有参数,在训练数据前加入一小段prompt,只训练prompt的embedding层。
hard prompt:指定prompt
1 | |
soft prompt:不指定prompt,让模型自行学习 ,对模型需要进行适配多轮才能有好效果
P-Tuning
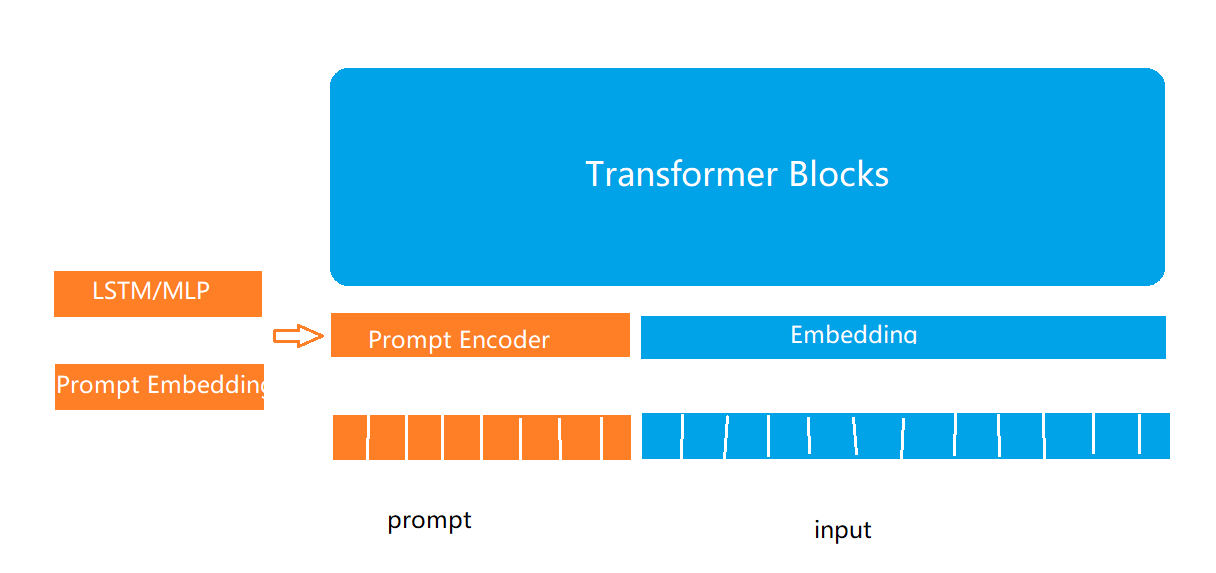
在Prompt-Tuning基础上,对prompt部分进行进一步的编码计算,加速收敛。
1 | |
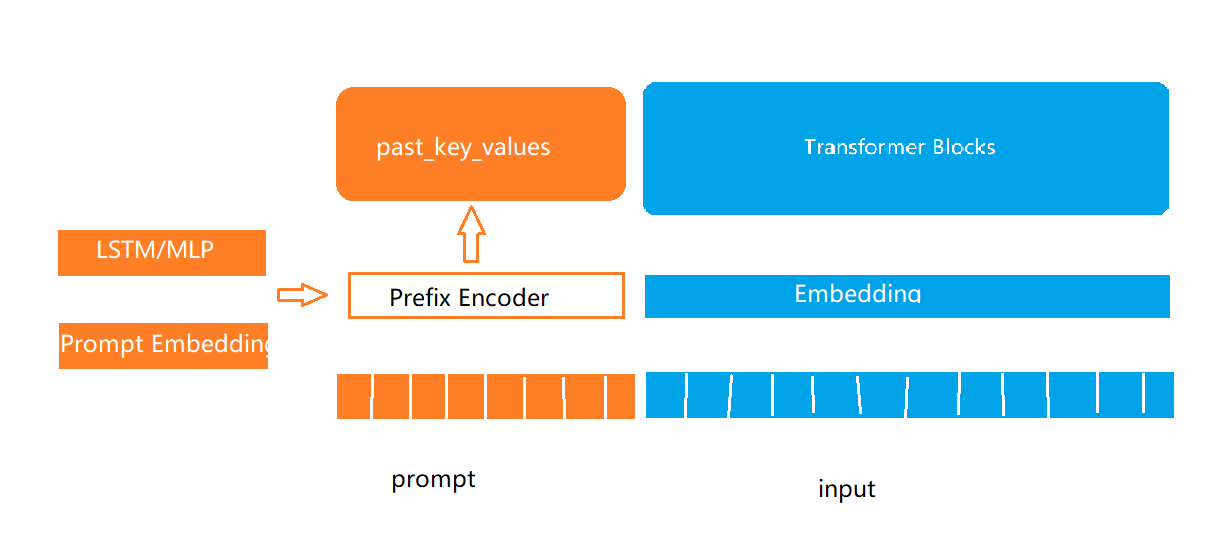
Prefix-Tuning
past_key_values:Transformer模型中历史计算过的key和value的结果,会存在重复计算,可将结果缓存。
通过past_key_values的形式将可学习的部分放到了模型中的每一层,这部分内容又称为前缀。
预训练模型
https://wendyflv.github.io/2024/06/02/预训练模型/